AI Research Highlights | Week 39, 2023
- Sep 25, 2023
- 3 min read
Updated: Feb 20, 2024

1. Textbooks Are All You Need II: phi-1.5 technical report
Source: https://arxiv.org/abs/2309.05463
Microsoft phi-1.5 has been released, and it outperforms most state-of-the-art open-source LLMs on multi-step reasoning tasks like GSM8k, HumanEval, and MBPP when training a small 1.3B model with high-quality data. This paper calls into question the widely held belief that the capabilities of LLMs are solely determined by their scale. The model can be found at Huggingface.

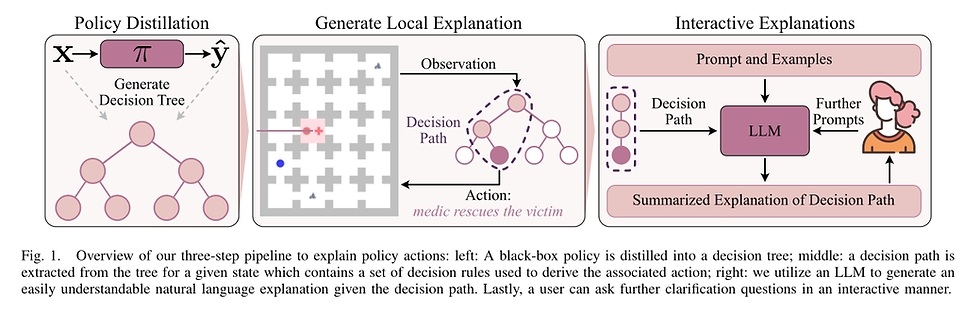
2. Explaining Agent Behavior with Large Language Models
Source: https://arxiv.org/abs/2309.10346
In this paper, researchers proposed a three-stage model-agnostic method to generate natural language explanations for an agent’s behavior based only on observations of states and actions. This approach enables users to prompt an LLM to reason about agent behavior in a way that yields plausible and useful explanations and causes the least amount of hallucinations.
3. Chain-of-Verification Reduces Hallucination in Large Language Models
Source: https://arxiv.org/abs/2309.11495
Meta AI researchers developed Chain-of-Verification (CoVe), a method using short-form questions to reduce long-form hallucination in LLMs. CoVe first (1) drafts an initial response; then (2) plans verification questions; (3) answers those questions independently and (4) generates its final verified response. This method successfully decreases hallucinations in a range of tasks.

4. PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training
Source: https://arxiv.org/abs/2309.10400
This paper proposed Positional Skip-wisE (PoSE) training that revolutionizes how we extend context windows of LLMs, potentially supporting infinite lengths. It successfully extends LLaMA to 128k tokens and has been verified on other LLMs (GPT-J, BaiChuan) and PI strategies (Linear, NTK, YaRN). PoSE significantly decreases memory and time overhead when compared to fine-tuning on the full length, with little to no performance impact.

5. LLMR: Real-time Prompting of Interactive Worlds using Large Language Models
Source: https://arxiv.org/abs/2309.12276
Researchers from MIT and Microsoft presented a Large Language Model for Mixed Reality (LLMR), a framework for the real-time creation and modification of interactive MR experiences using LLMs. LLMR can be deployed across platforms with high accuracy, satisfying its users.

6. LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models
Researchers from CUHK and MIT presented LongLoRA, an efficient fine-tuning approach that extends the context sizes of LLMs with limited computation cost and comparable performance to full fine-tuning.

7. BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Source: https://arxiv.org/abs/2309.11568
BTLM-3B-8K, a 3B open-source language model, was introduced in this paper. It uses just 3GB of memory with 4-bit precision, yet it requires 2.5x less inference computation than 7B models with negligible performance impact. This contributes to the availability of a sophisticated language model on mobile and edge devices. The model can be found at: https://huggingface.co/cerebras/btlm-3b-8k-base
8. LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
Source: https://arxiv.org/abs/2309.11998
LMSYS-Chat-1M is a large-scale dataset containing 1M real-world conversations with 25 SotA LLMs, collected from 210K unique IP addresses. This dataset helps understand human-LLM interactions in real-world scenarios. It can be found at: https://huggingface.co/datasets/lmsys/lmsys-chat-1m
9. CoT-BERT: Enhancing Unsupervised Sentence Representation through Chain-of-Thought
Source: https://arxiv.org/abs/2309.11143
CoT-BERT is a pioneering strategy introduced by researchers from Tsinghua University. It combines the Chain-of-Thought (CoT) process with text representation tasks, ending up in a two-stage approach for sentence representation: comprehension and summarization. CoT-BERT was shown to outperform a range of baselines and achieve state-of-the-art performance without relying on other text representation models or external databases.
10. Investigating the Catastrophic Forgetting in Multimodal Large Language Models
Source: https://arxiv.org/abs/2309.10313
Catastrophic forgetting is a notorious problem for fine-tuned models, especially in multimodal large language models (MLLMs). The authors proposed EMT, the first framework to evaluate the catastrophic forgetting problem in MLLMs through classification. EMT reveals poor classification performance retention for most tested models. Additional fine-tuning experiments on LLaVA indicate that while moderate fine-tuning is beneficial, excessive fine-tuning ultimately leads to catastrophic forgetting.

11. Stabilizing RLHF through Advantage Model and Selective Rehearsal
Source: https://arxiv.org/abs/2309.10202
Advantage Model and Selective Rehearsal are two novel methods developed by researchers from Tencent AI Lab in order to stabilize the RLHF training process, alleviating the issues brought on by reward hacking and catastrophic forgetting. Advantage Model aims to maintain balanced reward score distributions across diverse categories and examples. Selective Rehearsal identifies optimal examples for PPO training, encouraging the retention of crucial knowledge from the SFT stage.
12. The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
Source: https://arxiv.org/abs/2309.12288
If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". That is the reversal curse of LLMs, pointing to a lack of meta-learning ability, regardless of their size or the questions posed.

*The researchers behind the publications deserve full credit for their work.

