AI Research Highlights | Week 40, 2023
- Oct 9, 2023
- 2 min read
Updated: Feb 20, 2024

1. Large Language Model Alignment: A Survey
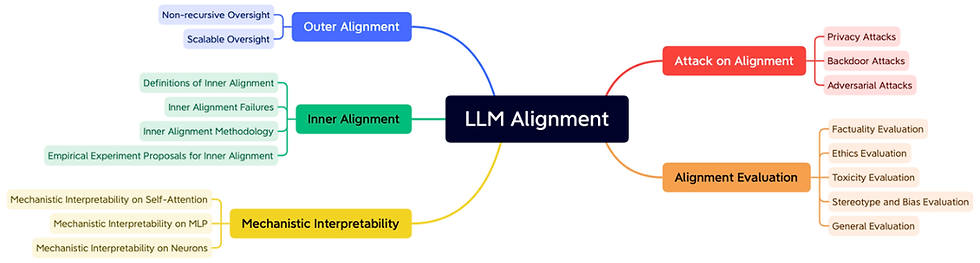
Source: https://arxiv.org/abs/2309.15025 A research team from Tianjin University published a review paper on large language model alignment, covering more than 300 references, and providing a macro perspective of this topic. They divided LLM alignment into three categories: outer alignment, inner alignment, and mechanical interpretability, and discussed the vulnerability and future directions of LLM alignment.
2. Natural Language based Context Modeling and Reasoning with LLMs: A Tutorial
Source: https://arxiv.org/abs/2309.15074
This paper introduced LLM-driven Context-aware Computing (LCaC), a computing paradigm that demonstrates the use of texts, prompts, and autonomous agents (AutoAgents) that enable LLMs to perform context modeling and reasoning without requiring fine-tuning of the model. The authors provided a detailed tutorial and 2 showcases.

3. Aligning Large Multimodal Models with Factually Augmented RLHF
Source: https://arxiv.org/abs/2309.14525
The researchers introduced a novel aligned end-to-end trained large multimodal model called LLaVA-RLHF that combines a CLIP and Vicuna for general-purpose visual and language understanding, alleviating the "hallucination" caused by the misalignment between 2 modalities. They proposed a new alignment algorithm called Factually Augmented RLHF (Fact-RLHF) that augments the reward model with additional factual information. The project can be found here.

4. A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future
Source: https://arxiv.org/abs/2309.15402
The authors conduct an extensive survey of CoT and its updated versions, including details in the method, frontier applications, future directions, and benchmarks. This survey is the first thorough investigation of XoT (refers to the use of step-by-step reasoning methods), paving the way for further research in this field.

5. Boosting In-Context Learning with Factual Knowledge
Source: https://arxiv.org/abs/2309.14771
This paper introduced a novel Knowledgeable In-Context Tuning (KICT) framework to further improve the performance of In-Context Learning (ICL) by fully exploiting factual knowledge (inherent knowledge learned in LLMs, factual knowledge derived from the selected in-context examples, and knowledge biases in LLMs for output generation), outperforming strong baselines over classification and question answering tasks.

6. AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Source: https://arxiv.org/abs/2309.16058
Scientists from FAIR proposed AnyMAL, a scalable way of building multimodal LLMs that reason over diverse input modalities and generate textual responses. This is a novel way to interact with an AI model. It achieves strong 0-shot performance in both automatic and human evaluation of diverse tasks with fine-tuned models.

7. Effective Long-Context Scaling of Foundation Models
Source: https://arxiv.org/abs/2309.16039
Meta presented a series of long-context LLMs that support effective context windows of up to 32,768 tokens. LLAMA 70B variant surpasses gpt-3.5-turbo-16k’s overall performance on a suite of long-context tasks. The results showed that having abundant long texts in the pretrain dataset is not the key to achieving strong performance, and long context continual pretraining is more efficient and similarly effective compared to pretraining from scratch with long sequences.

8. Qwen Technical Report
Source: https://arxiv.org/abs/2309.16609
Qwen Technical Report was released by Alibaba as the first installment of their large language model series. The open-source Qwen series, including Qwen-7B, Qwen-14B, and Qwen-Chat can be found here.

*The researchers behind the publications deserve full credit for their work.
